

 Global
Global  United States
United States 
What is a Vision Transformer?
As we are aware, today’s contemporary global village is uplifted with various advanced technologies, including Convolutional Neural Networks (CNNs) that form the foundation for image segmentation and recognition algorithms and other computer vision-related applications. Alongside these networks, Vision Transformers are emerging as considerable alternatives to the current state-of-the-art mechanisms. This is majorly because of their exceptional accuracy in performance and computational efficiency as compared to CNNs. These models are being applied in various applications, such as object detection and classification, medical imaging analysis, point cloud classification, autonomous driving, facial and action recognition, Optical Character Recognition (OCR), multi-model tasks like visual question answering, visual grounding and reasoning, satellite and remote sensing analysis, intelligent video analytics, robotic vision systems, etc.
The earliest mentions of Transformers were seen in 2017, when the models ran on attention mechanisms and performed NLP tasks. This was followed by pre-trained Bidirectional Encoder Representations from Transformers (BERT) in 2018. In 2020, Detection Transformer (DETR), an effective framework for object detection-related predictions, was introduced. Furthermore, towards the middle of 2020, the Generative Pre-trained Transformer (GPT-3) with 170B parameters came forth. These are also used in Natural Language Processing (NLP), such as in ChatGPT, a language model built on transformers that is GPT architecture. In this case, self-attention procedures are used to model dependencies amongst text and words.
Basically, a ViT transformer is a model introduced in a conference held in 2021 that can easily handle vision processing tasks. Although it was formed by computer vision and image processing services during the end of 2020, post the introduction of Japanese GPT (jGPT) that was used for image pre-training. It was first mentioned in a research paper published in the ICLR and discussed in this conference. The models mentioned were accessible through Google’s GitHub and were pre-trained on ImageNet-21k and ImageNet datasets. As of today, we can observe Image Processing Transformer (IPT), Segmentation Transformers (SETR), and Contrastive Language-Image Pre-Training (CLIP) and other ViT variants, such as DeiT, TNT, PVT, CSWin and SWin that are utilized for low-level vision-related, segmentation, and multimodality tasks. The current global market for vision transformers is estimated to be around US $217.5 million as of 2023 and is expected to surge and reach an approximate value of US $1.59 billion by 2030, increasing at a CAGR of 33.6% during this forecast period. In this blog, we will explore its working and applications, such as OpenCV face recognition.
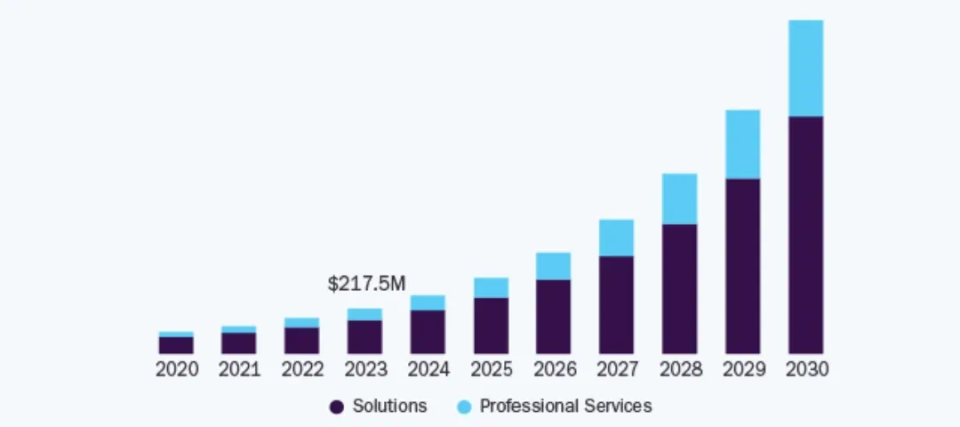
Source: Grand View Research
Growing market size of ViT vision transformer during the forecast period 2023 to 2030
How Does a Vision Transformer Work?
Architecture
Patches of images are sequence tokens, for example, words, while there are multiple blocks in the ViT encoder. Here, each block is composed of three processing elements of importance, which are as follows:
- MLP: MLP is a two-layer classification network known as a Multi-Layer Perceptron that has a Gaussian Error Linear Unit (GELU) at the end. The final layer or MLP block forms the output of the transformer and is called the MLP head. Once the output is obtained, softmax can be applied to the same to obtain classification labels in the case of image classification tasks.
- Layer Norm: This architectural layer checks the training process and keeps it on track, such that the model can adapt to the various images being fed.
- MSP: Multi-head Attention Network generates attention maps from embedded tokens, which are further used to focus on important regions or objects within the image. This concept is similar to saliency maps or alpha matting in CV-powered applications like OCR receipt scanners.
Other than these, each transformer block has two sub-layers, namely the feed-forward layer and the self-attention layer. The latter takes each pixel in the image as per its relationship with other pixels and calculates attention weights. On the other hand, once the output is received from the self-attention layer, the former applies non-linear transformation to it. Different parts of the input sequence can be attended simultaneously using the multi-head attention mechanism.
An additional layer, namely the patch embedding layer, separates the image into similar-sized patches that are mapped to a vector representation of higher dimension. These patch embeddings are fed into blocks for processing, and as and when the output passes the final transformer block through a classification head, a single completely connected layer showcasing a class prediction is obtained.
Working
In these models, the images recorded or used for training are presented as sequences, the labels for which are predicted. This allows ViT vision transformer to analyze the image structure in an independent manner. The patch-wise sequence of images is flattened into a singular vector through concatenation of pixel channels in a patch. Furthermore, the amalgamation is linearly projected to the desired dimension of the input image, such as in self-checkout automation in retail stores.
Simply put, the image is split into patches that are flattened to produce linear embedding of lower dimensions. Thereafter, positional embeddings are added, and the sequence is fed as input into the standard transformer encoder to pre-train it with fully supervised labeled image datasets. The downstream dataset is fine-tuned for performing actions like image classification.
The transformer model involves self-attention and multi-head attention mechanisms that may neither be CNN nor LSTM but uses skip-joining like ResNet. The former mechanism allows the transformer to capture long-range dependency and input data with its contextual information. It then assists the model to check various regions of the input as per their relevance and application, such as object-based image analysis.
Thereafter, it computes a weighted sum of the input based on the similarity between the weights computed and the features. With this, the model can capture more informative representations of the same and assign importance to the features for further capturing data. In short, vision networks learn about the network and align input data robustly using self-attention mechanisms that quantify pairwise entity interactions.
This kind of vision transformer backbone leads to the formation of attention maps that are basically matrices representing the input image regions over the model’s learned representations with respective importance. As the non-overlapping patches of the input image are fed into the transformer encoder for computer vision object detection, attention maps or visualizations of attention weights between all tokens and each token or patch in the image.
Every token attend to all other tokens to calculate a weighted sum of representations and generate an attention map using self-attention mechanisms. Trainable line layers model the positional embeddings so that better resolutions can be fine-tuned when two-dimensional representations of the pre-trained position embeddings are performed.
Comparison
The vision transformer backbone outperforms that of CNNs, as it requires four times fewer pre-training computational resources (FLOPs). It showcases low inductive bias when trained on smaller datasets; this might lead to data augmentation or model regularization. ViT models were first designed for text-based tasks. Apart from image recognition and classification tasks where CNNs utilize pixel arrays and ViT splits the image as tokens, transformers can also outperform NLP and smart trash bins type applications for more efficiency. It accurately embeds information and encodes the relative location of the patches of images globally, which enables ViT to even reconstruct its structure as learned from training data.
ViT models can assign labels to an image as per its content, showing better promise in terms of parametric accuracy than CNNs like VGG, YOLOv3, YOLOv7, and YOLOv8. When pre-trained with an apt number of datasets, they can even perform better than ResNet models against attacks. A transformer is considered a deep learning model under the umbrella of machine learning that specifically uses self-attention layers to weigh input data sequences as per their significance in Computer Vision (CV) and NLP applications. Industries have currently replaced RNN models, such as Long Short-Term Memory (LSTM) for performing NLP-related tasks and AI defect detection.
Although it is true that CNNs are easier to optimize than these models. The ViT transformer’s performance is largely dependent on the decisions of the optimizer, dataset-specific hyperparameters, and the network depth. However, maximum efficiency, stability, and precision can be obtained by combining the transformer with a CNN front end. This is because the former leverages a 16*16 convolution with a 16 stride as compared to the latter with a 3*3 convolution and 2 strides.
When combined, the CNNs turn pixels into feature maps, which are converted into a sequence of tokens to be put in the transformer. It then applies the attention mechanism to create an output token sequence that gets reconnected to the feature map through a projector. Pixel-level details result in a lower number of tokens for ease of navigation, studies per token, and reduced costs.
As we are aware, ViT models require larger datasets before fine-tuning processes, in the absence of which ResNet or EfficientNet can be used that do not utilize MLP layers, and the number of classes in the dataset can be reduced. ViT can be considered an excellent option for learning high-quality image features, but it showcases inferior accuracy versus performance gains. Given its accurate results, its runtime is very high when compared with ResNet or MobileNet.
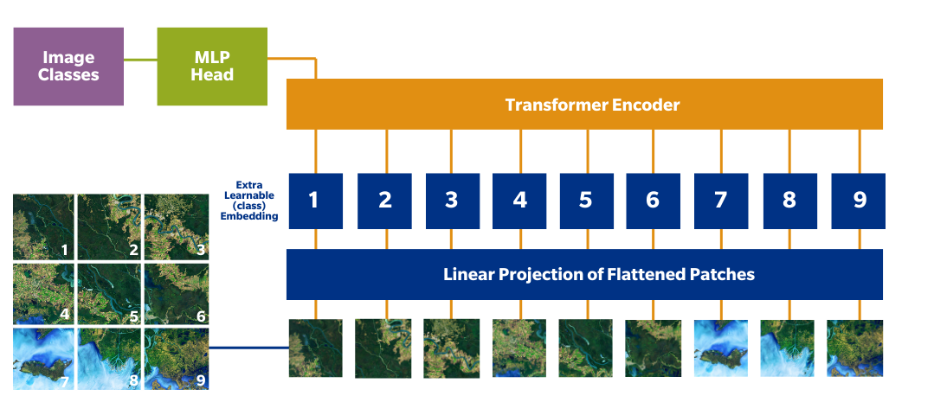
High-level working of ViT vision transformer
Various Applications of a Vision Transformer
Supervised vs. unsupervised learning or semi-supervised methodologies for the development of new CV-based scalable and generic architectures that can handle intensive large dataset training. This is where ViT models generate prominent results given their wide scalability. There are various real-life applications of computer vision in healthcare and others developed using ViT models, such as the following.
1. Anomaly Detection: A transformer-based localization network and anomaly detection in images require the combination of patch embedding and reconstruction approaches. Embedded patches feature spatial information that is preserved using transformer models for AI pattern recognition. This is used to localize regions with anomalies when processed using a Gaussian mixture density network.
2. Image Classification: A common CV application resolved using transformers when large datasets are provided. A combination of CNNs and ViT transformer can result in the image’s local information encoding, as the latter showcases locally restricted fields of reception, such as in autonomous driving systems.
3. Image Segmentation: Dense Prediction Transformers (DPT) are semantic segmentation models that apply vision transformers to images. DPT is also used for molecular depth estimation and vision inspection system, where it outperforms CNNs in terms of relative performance.
4. Autonomous Driving: Transformers form the basis of the cross-attention modules utilized in different types of neural networks and are empowering many autonomous vehicles. They are majorly embedded in the building block of the vehicle that caters to image-to-BEV and multi-camera fusion.
5. Action Recognition: Transformers are also used in video classification applications for human activity recognition, where the model analyzes the long sequences of input video to extract spatiotemporal tokens and encodes the same through a series of layers.
6. Image Captioning: ViT models perform accurate and advanced image categorization through caption generation alongside labels, such as in automated attendance systems. They learn the representation of a given data modality alongside the label sets to generate a descriptive text for the input image.
Wrapping Up
In this blog, we went through the working of vision transformers and understood how they utilize multi-head self-attention mechanisms in CV irrespective of image-specific biases to bring awareness to the developed model. As the transformer encoder processes the series of positional embedding patches formed from images split by the model, the ViT understands the input’s global and local features visualized by attention maps for further improvement. The computational efficiency and highly precise CV-based task performance of these models with vision transformer backbone have received considerable importance over CNNs and can be moderated with low training datasets and project time. KritiKal develops ViT models that are easy and quick to deploy through a straightforward and less complex approach, thus emerging as necessary foundations for various applications. Please get in touch with us at sales@kritikalsolutions.com to learn more about our vision-based products, platforms, services and realize your business requirements.
Kota Maneesh Krishna currently works as a Senior Testing Engineer at KritiKal Solutions. He is proficiently skilled in manual automation, API, mobile, and performance testing, Selenium, WebDriver, Appium, JMeter, CI/CD integration using Jenkins, Java, Python, and more. With his ability to work efficiently in teams and adept understanding of developing and testing high-quality software solutions, he has assisted KritiKal in delivering various projects to some major clients.