

 Global
Global  United States
United States 
A receipt is a legal document that states the items bought and billed amount as evidence of the purchasing act. It consists of personal, business finances and transaction of expenses. Since the medieval times, receipts have been a part of civilization as and when transactions took place over the centuries. With time, as the human population and businesses across the globe flourished, it became a necessity that mundane tasks be accomplished using machines, where human minds and subsequent thought processes could be utilized for more creative works.
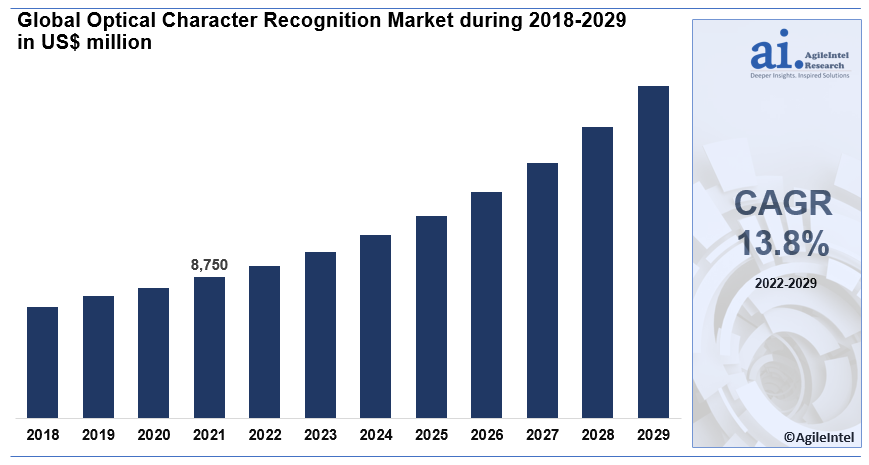
Thus, the adoption of Optical Character Recognition, for receipt reading and processing, in the early 20th century proved to be a game-changer from the vintage procedure of manual data entry. Now, systems are able to efficiently extract, enhance, sort, process, analyze, manage, store and track financial data without any human intervention. Moreover, the global OCR market is likely to be valued at about $27.16 billion in 2028 from $11.65 billion in 2022, increasing at a CAGR of 15.4% during this forecast period. (Stratview Research)
Given the surging importance of this technology, let us now go through a comparative analysis of manual data entry and the functioning of an OCR receipt scanner for a clearer picture.
What are OCR Receipt Scanners?
Every company deals with receipts, be it as a payment of services or products, whether they are electronic or physical copies versions, and that is why receipts have become an inseparable part of all types of businesses. Problems arise when various departments in the company need to deal with millions of receipts being formed in varied geographies, which makes them impossible to be processed manually at a stretch. Not to mention the increase in labor costs and difficulties of dealing with product royalties, customer dissatisfaction from longer turnaround times, fraudulent issues and internal travel expenses of employees who may be thousands in numbers, makes it altogether a cumbersome process with an even greater negative impact on businesses.
Tackling these daily life issues is the Optical Character Recognition technology powered by AI-based OCR engines, that scan and capture the physical or e-receipt data as an image file, convert it into machine readable text, then recognize, extract and classify individual characters of the receipt in the form of key-value pair extraction automatically within seconds. Here, key-value pair extraction is on the basis of a historical dataset which consists of pre-defined parameters to be extracted such as VAT percent, recipient name, payee name, merchant address, billed amount, item details and so on. This conveniently reduces processing times up to 80% as compared to manual data entry as well as intercepts the bottleneck of processing huge amounts of voluminous receipts.
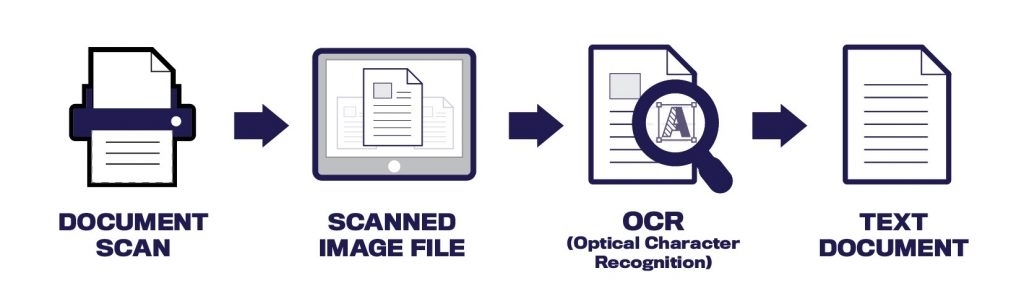
Depending upon specific business needs, one can switch to Desktop OCR systems software, Wands (OCR reading units attached at point-of-sale terminal), tablet and mobile-based OCR receipt scanner app or even web-based OCR servers provided by OCR vendors.
Why Switch to OCR from Manual Data Entry
With OCR receipt scanning one can easily automate business process and gain the following advantages which one may not have been able to with manual data entry –
Minimize fraudulent activities
With OCR integration, businesses can accurately identify fraudulent actions such as submitting the same receipts; these entries need to be removed from the accounting software or program. Another case would be altering certain elements like total amount in the loyalty program or franchise’s receipt image by using Photoshop. Such deviations would be detected at as minute as the pixel level, by comparing corresponding values such as VAT with billed amount and by checking Exif data anomalies, which may be missed erroneously during manual data entry.
Lower turnaround time
With today’s era transiting rapidly, increasing customer loyalty with speedy document processing facilities as well as employee retention with faster reimbursement for travel expenses and more has become a must. By repairing this benefit of data extraction that occurs in about 3-5 seconds, companies can give tough competition in the market where manual data entry still persists, which humanely takes at least 1-2 minutes during sorting, reading, checking and entering receipt data into the accounting software. Especially in the case of franchises etc., receipt eligibility can be checked in a matter of seconds as compared to weeks taken for the manual process, building trust and brand of the parent company and managing expenses effectively.
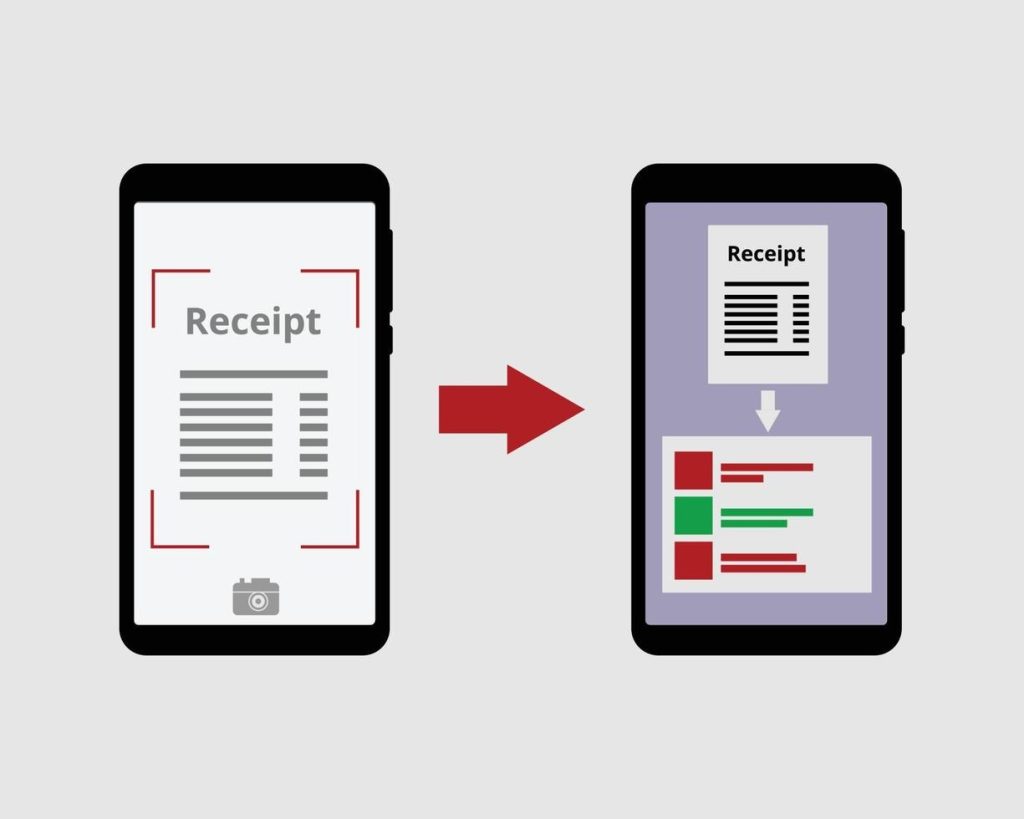
Limit human errors
What makes a business stand out from the rest is committing minimal errors in all phases of the business process, which is highly unlikely during manual data entry of thousands of transactions. According to a Springer report, outliers in this case can be as high as 26.9%, whereas error rates range from 0.55% to 3.6%. In contrast, OCR systems provide a minimum accuracy of about 95% in text recognition by eliminating the risk of distraction, keystroke errors, misreading, clerical errors, issues related to handwritten or faded text, unevenly scanned images, unrecognized fonts or languages and more for better decision making from correct data insights.
But at the same time, a hybrid approach blending human intelligence with the accuracy of AI, commonly referred to as Human-in-the-Loop or Human-in-the-Middle automation (HITL), involves a proof-reading employee after the OCR systems perform receipt data extraction, averaging the accuracy rate to almost 100%. It is usually done when it is already known that a particular region or store is bound to produce problematic receipt build-up or, as and when the confidence score threshold comes to be lower, let us consider, lesser than 70%, in case of mismatch in approval workflows of the established business rules. For example, a checkpoint at any billed amount value less than $200 in the receipt can be checked via HITL.

Lower operational costs
Employees get freed from investing their time in mundane, tedious and repetitive data entry processes, therefore, indulging in creative tasks and core business operations and saving costs by up to 75%. Besides, businesses can leverage intelligent automation for longer payback periods as an addition to saving costs.
Now on comparing the savings with respect to time, one can see clear cut profits, per say, processing a receipt manually takes about 1-2 minutes that makes for about 50 receipts in an hour. Given that the average hourly wage in the USA is $28.34, that sums up for $0.57 as the cost of manually processing one receipt. In contrast to this, processing time by OCR systems can be as low as 18 seconds per receipt, that makes up for a minimum of 200 receipts on an hourly basis, leading to an approximate processing cost per receipt to be around $0.142. On adding the average cost of OCR software per receipt that is $0.015, one observes that the total cost comes out to be $0.157, thus saving around $0.413 or a direct improvement of 72% for processing a receipt. This value may further increase on considering the overall differences in time required to process longer receipts and the number of employees required.
Security compliance
A major factor in attaining customer loyalty is the value add of user-friendly receipt scanner API and data discretion. Many times, receipts consist of personal information such as mode of payment, debit or credit card number, payee name, contact, bank name, email or home address. This makes it necessary to handle such sensitive data in compliance with General Data Protection Regulation (GDPR), if the US based company is operating in the European Union or European Economic Area or has to deliver products or services in the same as well as in compliance with California Consumer Privacy Act (CCPA) and the Health Insurance Portability and Accountability Act (HIPAA) for protecting sensitive patient data from insurance companies and healthcare providers in the USA.
This fine can be as high as 2% of the total annual revenue of the business. At the same time, data breach policies can lead to a fine of $50,000 or more costing $500 per customer who was unaware of the breach. Although, businesses are liable to exhibit the right to forget in case they conduct infringement unknowingly and store personal data that they never required in the first place. To avoid such situations from arising, OCR receipt scanning software can be trained to identify sensitive data fields, for instance, with personally identifiable information fields (PII), followed by data anonymization or redaction using data masking
Enhancing OCR Receipt Scanners
OCR image scanning and processing can be improvised multifolds using Intelligent Document Processing (IDP) with intelligent algorithms, while automated extraction, storage and management can be empowered with Robotic Process Automation. IDP can enhance scanned receipt image quality, per say brightness, rotation, tables recognition etc. and thus, improvise recognition accuracy. Now-a-days some IDP software do not need to be pre-trained or be supported by manual rules, due to the aid of Machine Learning (ML), Artificial Intelligence (AI) and Deep Learning (DL) modules that even provide data insights.and analysis.
Although employees can recognize a lot of writing styles and fonts, IDP powered OCR machines need to be trained with structured and unstructured image or document datasets containing all sorts of possible complex fonts, spelling errors (capitals), single column page errors (compliance issue), punctuations, text sizes (big, small, more than 5K characters), and styles (bold, italic, cursive, paragraphs, indentation and line breaks) for producing accurate extraction results. Natural Language Processing (NLP) comes into picture where multilingual documents may be involved. Furthermore, Robotic Process Automation (RPA) can be used to directly integrate and store scanned information to accounting or mailing software.
What KritiKal Offers
By accepting KritiKal as your OCR service provider, well-organized and decluttered desks are just a click away, for it provides you with systematic, swift and hassle-free receipt image upload and processing services.
Extensive Features & AI Models We Work With
Let us take a look at some attractive features of our AI-powered end-to-end IDP platform that works on OCR engines for information extraction, Computer Vision and NLP algorithms:
- Input Variety: It takes all-sided inputs in multiple formats like images, invoices /receipts /purchase orders /claims /KYC documents, .pdf, .xls, .jpeg, .tiff, .png, .jpg, .html, .csv etc, and extracts fields from structured, semi-structured and unstructured data efficiently.
- Text Detection & Recognition: Accurate word detection using AI models and OCR engine to detect and recognize text precisely. Faster inference with OpenVino and TensorRT optimizations is provided.
- Layout Detection: DL based AI models to detect different layouts like paragraphs, titles, etc. and parse them efficiently for data extraction and further processing.
- Table Parser: AI models utilized for extracting information from tables in its original structured format.
- Document Localization & Correction: Vision models to localize, align and transform the documents for further processing.
- Text Restoration: AI models to restore broken or faded text and shadow removal for better text recognition.
- Key-value Information Extraction: NLP models based accurate and intelligent data extraction of essential content from different types of segments in documents like tables, paragraphs, lines, etc. and data post processing. It has active learning modules for improvising on field recognition as usage multiplies.
- Structured Information Extraction: Also known as Named Entity Recognition, where our NLP models locate, extract information and classify entities present in unstructured text into predefined categories like Receipt No, Biller Address, Receipt Organization etc.
- Production Ready: Dockerized for on-premise as well as API based access for cloud deployment and integration with apps like Wave, Excel, Outlook etc.
- Customizable: Solution can be fine tuned and customized according to requirements. Output format can be in the required structured data format like .docx, .pdf, zip, .csv etc. and with high dot per images. You can enable or disable modules to extract information at different levels.
Conclusion
We saw the strengths and weaknesses of manually entering receipt data and by using Optical Character Recognition technology, where given the aforementioned benefits, processing receipts will never be as tedious as in the traditional methods. Although the choice between both of these depend upon specific business needs, receipts volume, available budget and the required level of accuracy, flexibility and applications, a hybrid approach of OCR based data extraction followed by manual verification of critical data entries can minimize errors, generate exportable, accessible, portable results as well as increase storage and operational efficiency.
KritiKal has supported various businesses all through their transition journeys from manual data entry processes to OCR systems according to specific business requirements. We have worked in the past with some major US based clients and provided them with OCR and IDP related services. Please call us or mail us at sales@kritikalsolutions.com to avail our services.

Hitesh Suyal holds the position of Associate Architect at KritiKal Solutions. He has over 7 years of experience with a demonstrated history of working in the Information Technology and services industry. With his strong engineering background skilled in Python, Computer Vision, Deep Learning, OpenCV, Spyder, Microsoft Visual Studio C++, Amazon Web Services (AWS) and more, he has helped KritiKal in delivering successful projects for some major clients.