

 Global
Global  United States
United States 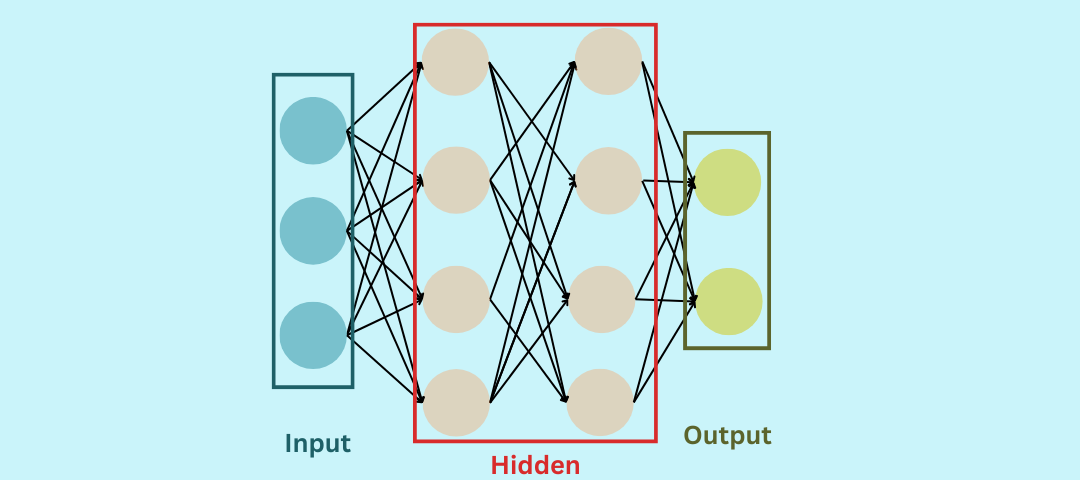
Neural networks, a sub-discipline of deep learning, were basically developed to mimic the human brain functioning. These complex computational models consist of various interconnected processing units called nodes, also known as neurons, similar to those present at the end of axons in the brain that are capable of processing and transmitting data, recognising hierarchical patterns, enabling machine learning and decision making. Deep learning refers to one of those enabled machine learning fields that are made possible to function with artificial neural networks. On comparing, deep learning versus traditional neural networks (NNs), we observe that these NNs require multiple processing layers (unlike shallow NNs with one hidden layer) that extract high level data and their features. Such type of machine learning can model complex problems and solve them by learning data relations within complicated patterns. With advancements in dataset availability and higher computing power (cloud, specialized hardware like GPUs), it has become common practise to train and utilize deep learning in developing algorithms for various applications such as self-driving cars, detecting developmental issues in children through CT and X-ray scan analysis, natural language processing, Large Langauge Models (LLMs) such as ChatGPT, handwriting and speech recognition, image processing and AI image generators like DALL-E, recommendation systems and predictive AI models like weather forecasting, stock market prediction, etc.
A Brief Note on Deep Neural Networks
Deep Neural Networks (DNNs) are extensively architected versions of Artificial Neural Networks (ANNs) that have multiple hidden layers between the input and output layers. ANNs are a type of computing architectures that categorize multiple input patterns, reduce overall complexity and provide single output (prediction or classification). When we throw light on previously discussed topic of comparing deep learning versus neural network earlier, both composed of nodes, we observed that nodes are artificial neurons determined by a non-linear function of a weighted sum of multiple inputs received, where a mathematical formula is incorporated per node with different weighs assigned to each variable. These nodes are collectively sequenced into layers, where series of non-linear transformations occur, for instance, outputs of the initial layer act as the inputs for the latter only when the input exceeds a certain threshold as per the formula. DNNs use diverse functions as compared to normal ANNs, thus, making them more efficient and subtle in learning and evaluating complex data patterns and features without any manual feature engineering interference. Here in this context, deep refers to dense architecture of neural networks, including functions of higher complexity in units in single layer as well as in different layers.
On comparing deep learning versus neural network of traditional times, we observe that DNNs are more accurate models due to the fact that they are built with larger images, textual or numerical datasets that are managed over cloud, and are therefore, able to capture patterns of higher complexity. With the help of DNNs, many breakthroughs were achieved such as reduction in speech recognition errors by 30% and in image recognition errors from 26% to 3.5%. The architecture of DNNs is created in a manner that the developer can choose how many layers would handle data complexity while the training (learning during developmental phase) of the network determines weights. Here, weights signify the adjustable numerical values placed between nodes (or neurons), assigning the connections strength and direction of informational flow within nodes, thus controling the influence of one unit over other. Similar to weights, biases are default values added to each node that help all neural networks in adjusting their predictions as per the dataset’s tendencies. This is followed by application of the activation function, where optimized inputs from the previous layer are filtered before being passed to the next layer. With time and datasets of different types, representations and higher complexity, neural networks including DNNs experience inference phase post-production, where prediction of output becomes more accurate as compared to actual expected decision progressively.
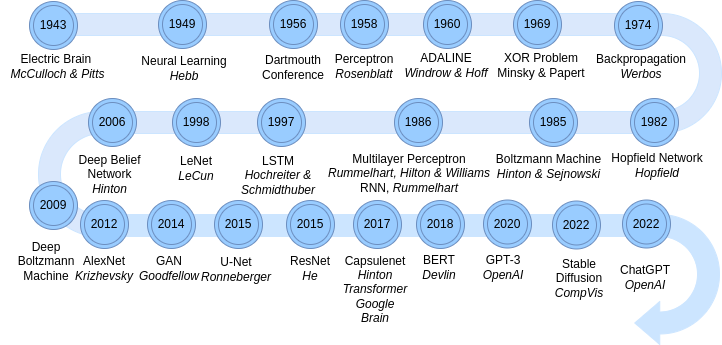
Timeline of development of types of Neural Networks
Let us take a real life example to understand the working of DNNs better. In case, we wish to predict weather of a certain region during the next day, we would need to consider factors like wind currents, current temperature data of the region over a month or week, and other factors like rate, amount of precipitation, atmospheric pressure, weather of nearby regions, cloud movements mph, solar radiation received in the region W/m² etc. Let us say, neural networks assign (decided by developers during training, still a black box during learning or inference) wind currents more weight, it then takes it as an important factor for weather prediction. In addition to this, for example, the network has seen occurences in previous datasets that if the wind currents flow at a speed of more than 22 mph it is likely to rain, it will assign positive biases to the nodes that process data values in this range. For the neural network to arrive at this proposition (rule or decision), the data must have passed through various hidden layers, for example, any wind current data output below 18 mph processed at the initial layer, must have not crossed the threshold so as to be processed as next layer’s input. In case data falls in the range 18-21 mph, it may get across the next layer for processing and flagged if the value exceeds 21 mph in the final layer, to be categorized as torrential thunder storms. Moving further in this blog, we would be discussing neural network types and their working.
Deep learning can be utilized for reinforcement, unsupervised as well as supervised machine learning. In case of supervised learning, labeled datasets with target variable and input features are provided for neural network to train upon, for example in case of RNN, CNN etc. The network backpropagates and learns how to perform better prediction, classification, language translation etc. from difference obtained between actual and expected result. On the other hand, in case of unsupervised learning, neural network is subjected to unveil hidden patterns, clusters and relations present within unlabeled datasets, such as in case of Autoencoders, GAN etc. for anomaly detection and dimensionality reduction. Reinforcement machine learning involves progressive maximizing and cumulation of rewards generated as per NN’s decisions, policies and actions in an environment, for example, in case of Deep Q networks, Deep Deterministic Policy Gradient (DDPG) for performing tasks like robotic actions etc.
Types of Deep Neural Networks
On the basis of interactions between nodes and the structure of their interconnected layers for tackling different dataset types and problems, there can be multiple types of neural network architectures. These architectures are empowered by multiple hidden layers for respective DNN or deeper versions.
1. Feedforward Neural Networks (FNNs)
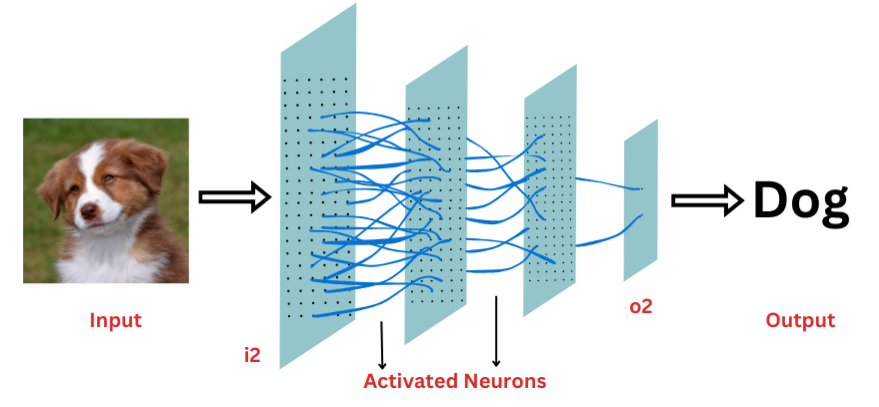
These are simiplistic artificial neural networks that in which information flow is linear and unidirectional that is from input layer (i2), followed by one or many hidden layers where each node calculates the weighted sum of inputs and performs the activation function. Thereafter, ultimately passing it to the output layer (o2) without subjecting preliminary outputs to cycles or loops, and adjusting weights and biases in the training itself in order to minimize errors between actual and predicted outputs. These are used to process and capture patterns in complex hierarchical data representations for performing classification, regression and applied functions such as speech recognition, natural language processing (NLP), predictive modeling, image recognition and classification, etc.
2. Recursive Neural Networks (RecNNs)
These are extended versions of FNNs that introduce recursive connections within their multiple stacks of their deep neural network layers and are suitable for dealing with hierarchical data structures like parse trees, as well as subsequent applicable tasks such as natural language processing, parsing and sentiment analysis.
3. Radial Basis Functional Neural Network (RBF)
RBF neural networks are another neural network type originated from traditional Feedforward Neural Networks that transform their inputs to outputs by using a set of non-linear radial basis functions. These neural networks are usually composed of input layer, one hidden layer and output layer as compared to multiple layers in other NNs as explained in the neural network diagram. These functions calculate the distance between various predefined centers present in the hidden layer and the input layer. The connections between the hidden and output layer consist of weights and biases that are trained using backpropagation or other supervised learning algorithms, making it possible to generalize easily, tackle problems with larger datasets and obtain accurate predictions through extensive training in case of deep learning. The outputs obtained from the hidden layer are combined linearly to produce the final output. RBF neural networks are used for pattern recognition and classification, time-series analysis and prediction, financial forecasting, control tasks, object recognition, etc.
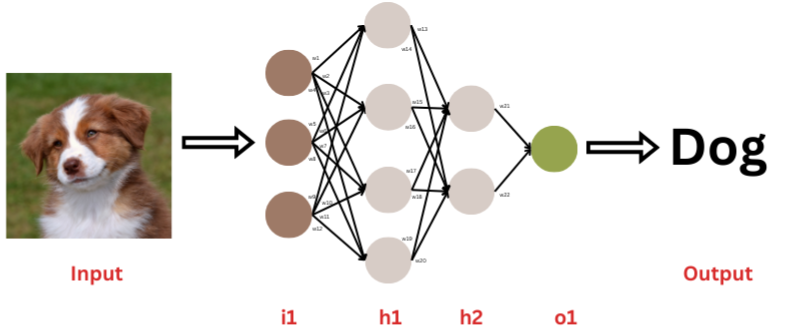
4. Multilayer Perceptron (MLP)
Perceptrons were the earliest single-layered type of neural networks developed that were capable of resolving only non-complex linearly separable problems (data can be separated into two categories), where they received input, applied weights (w1 to w22) to input, summed them, processed it further through activation function and produced an output (0 or 1, with respect to sum being above or below threshold function). Later on, multiple layers of perceptrons were brought together, where each layer consisted of many perceptrons, thus, it is a fully connected as can be seen in the image. This formed another type of FNN that came to be known as Multilayer Perceptron. Similar to FNN, input layer (i1) receives raw data, output from this layer is fed after initial processing to hidden layers (h1, h2) as input, that transforms it to a suitable form which can be properly classified by the output layer (o1) for final prediction. MLPs are used in signal processing, speech recognition, time-series analysis, NLP & control systems.
5. Recurrent Neural Networks (RNNs)
Recurrent neural networks are composed of a series of recurrent nodes that process the input sequential (text and speech) data like time-series, pass it through the consecutive layers (i3, h3, h4, o3), but at the same time, assist the network in maintaining an internal state or memory of previously entered inputs and output generated, such as sequential informational relations and temporal dependencies. When these nodes proccess new input data, they also take in the output obtained in the previous cycle, thus maintaining and expanding the memory, unlike Feedforward neural networks and RecNNs. Though, similar to RBF neural networks, certain weights (w1 to w20) associated with the neurons are adjusted during training through backpropagation. Because of such an ability, RNNs are well-suited for performing functions related to natural language processing such as speech recognition, language translation, text generation, time-series prediction etc. However, a common challenge associated with such DNNs relates to exploding and vanishing gradients, causing long-term dependencies.

6. Long Short-Term Memory (LSTM)
LSTM is a deep neural network type that is an improvised version recurrent neural network that eliminates the aforementioned shortcoming related to long-term dependencies. It has a gating mechanism across its network, where an input gate that determines important information that is required to be stored in the memory cells, a forget gate removes unrequisite information from them, and the output gate determines passable information for the next layer. Since, these neural networks are capable of maintaining information over extended periods of time with minimised differential error between actual and predicted outputs, these pose as suitable DNNs for time-series prediction, text translation, sentiment analysis, image, object, speech, handwriting and scene recogniton.
7. Convolutional Neural Networks (CNNs)
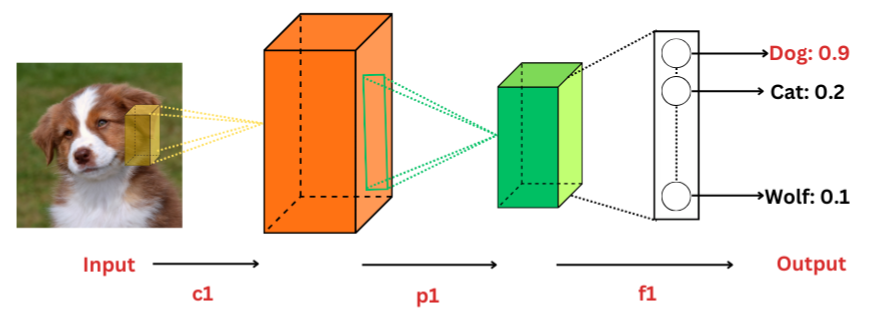
These DNNs process data which are grid-like in nature such as images and videos. These neural network types are made up of interconnected convolutional layers (c1), pooling layers (p1) and fully-connected layers (f1). As and when each layer receives input image, the complexity of layers increases and larger portions of the image are identified and processed gradually so as to produce a simplified output. Within multiple convolutional layers, filters are applied to extract and learn spatial hierarchies of features in the input image, output of these layers is combined, simplified and passed on to the pooling layers that reduces the image dimensions, therefore, downsampling it. The subsequent output obtained from these is passed through fully-connected layers, where objects in the image undergo classification or prediction. Due to ability of hierarchical learning, these can easily recognise patterns at various abstraction levels, thus, rendering them as robust for different positions, scale and orientations. These are largely used in self-driving cars, facial recognition, object detection (like Fast R-CNN, YOLO, SSD, R-CNN), and other image recognition and classification (like AlexNet, VGG network, MobileNet, ResNet) problems.
8. Autoencoders
Autoencoders are neural networks that consist of encoders for compressing input unlabelled data into a lower-dimensional latent representation as well as decoders for reconstructing it to original format from the latent space. It is thus suffice to say that with this ability they can identify features of utmost importance in the input data and are therefore utilized for anomaly detection such as in spacecraft sensor data, dimensionality reduction, image denoising, feature extraction and learning, predictions and other unsupervised learning applications.
9. Generative Adversarial Networks (GANs)
GANs are composed of two types of neural networks, firstly generators, that generate realistic fake data and secondly discriminators, that authenticate real and generated data both. During training, the generator learns to produce synthetic data, while discriminators learn to distinguish synthetically generated data from real data. A feedback is provided to the generator about the same which indirectly trains it by penalizing it for implausible result production. In this case, adversarial training is used to enhance the model’s performance and security against malware and other attacks by labeling such inputs as misleading towards wrong predictions and classifications. Through multiple iterations of training against the same or similarly harmful or fake input data, GANs are able to generate high-quality data, therefore making them useful for data augmentation, deepfake image and video syntheses and style transfer.
10. Others
Few other deep neural networks types that are empowered by including multiple hidden layers for accurate predictions and classifications can be Siamese Networks, Sequence to Sequene (Seq2Seq) Models, Modular Neural Networks (MNNs), Deep Belief Networks (DBNs), Liquid State Machines, Extreme Learning Machine, Deep Residual Network (DResNet), Transformer Neural Networks (TNNs) etc.
How Does KritiKal Support You with DNNs?
KritiKal Solutions has over 21 years of experience of working over applications of Neural Networks and Deep Learning fields. We have accomplished development of state-of-the-art computer vision solutions such as traffic analyser and classifier, alongside intelligent document processing, planogram compliance solution, vehicle detection solution, smart parking management systems, healthcare-related solutions like hair segmentation, vision-based keyboard, rubik’s cube, other edtech applications and much more. Join hands with us to avail our expertise in Deep Neural Networks and experience tremendous growth in your business. Please call us or mail us at sales@kritikalsolutions.com.
Conclusion
In this blog, we delved into various types of neural networks in deep learning categorized based on their input data and functions. Modern deep neural networks showcase industry-agnostic flexibility and ability to resolve highly complex problems all the while continuously learning and improving performance. Ultimately, on observing the unstoppable growth of DNN-related research, it is suffice to say that there is no limit to this expanding list of variants due to introduction of higher computing resources and the innumerable ways their in-built nodes can interact across millions of layers in the neural network architecture.

Kavya Niju currently works as a Vision Systems Engineer at KritiKal Solutions. She has comprehensive technical proficiency in Python and OpenCV. She also has a strong command over Java, C, MATLAB and other programming languages. With her advanced skills and collaborative team playing efforts, she has helped KritiKal in timely deliveries of various projects related to image processing etc.
Heidy Oliver
November 22, 2025Excellent explanation — the visuals were worth a thousand words.
Ivy Bell
January 30, 2026This was beautiful Admin. Thank you for your reflections.
Journey Bradshaw
February 1, 2026Good post! We will be linking to this particularly great post on our site. Keep up the great writing
Penelope Gutierrez
February 2, 2026This is my first time pay a quick visit at here and i am really happy to read everthing at one place
Simon Bender
February 3, 2026Pretty! This has been a really wonderful post. Many thanks for providing these details.
Online Education & Certifications
March 11, 2026For the reason that the admin of this site is working, no uncertainty very quickly it will be renowned, due to its quality contents.
men puma
April 12, 2026You really know your stuff.
bonus
April 24, 2026Your review is greatly appreciated, thank you!
Kaydence Hahn
May 7, 2026This was beautiful Admin. Thank you for your reflections.
Hijab Styles
June 7, 2026hocam gayet açıklayıcı bir yazı olmuş elinize emeğinize sağlık.
WEDDING DRESSES
June 14, 2026Nice post. I learn something totally new and challenging on websites
Sell House Faster
June 14, 2026websitem için çok işime yaradı teşekkür ederim
fashion Email Automation
June 14, 2026Çok işime yaradı bende bunu nasıl yapacağımı araştırıyorum. Paylaşım için teşekkür ederim.
roof replacement cost
June 14, 2026Ne zamandır web sitelerim için aradığım içeriği sonunda buldum. Bu kadar detaylı ve net açıklama için teşekkürler.