

 Global
Global  United States
United States 
In today’s competitive era, businesses need to undergo continuous improvement to keep up with customer expectations. They strive to make their operations, offerings etc. smarter and easier as a cost-effective measure, by using machine learning algorithms. For example, introduction of facial recognition in Samsung smartphones as a security feature and using machine learning for credit card fraud detection by American Express in the USA since 1950s etc. Within machine learning, there can be two approaches or fundamental paradigms that help in creating such applications, that are supervised and unsupervised learning. As the names suggest, supervised learning uses labeled input and output data for training to predict outcomes, while unsupervised learning doesn’t. It is necessary to understand the differences between the two based on algorithms, characteristics, challenges and techniques used, for developing effective machine learning solutions.
Let us take an example of supervised learning model is required to predict the commute time based on factors such as time of the day, weather etc. The model needs to be trained regarding the commute time during rainy weather and other factors by using annotated data prepared through human intervention. This allows the model to predict more accurate answers than in the case of unsupervised learning, where the latter learns the inherent structure of the unlabeled input data. Take another instance, where the unsupervised learning model identifies certain products that are often bundled together during purchase by customers. This learning can be useful for developing recommendation engines in e-commerce apps, but ultimately even such predictions require human intervention to validate the bundling or prediction of output.
The global market value for unsupervised learning is $4.2 billion as of 2022, which is projected to increase at a CAGR of 35.7%, till it reaches a value of $86.1 billion in 2032. While the global market value of supervised learning was reported to be $7.5 billion in 2021, it is steadily growing at a CAGR of 33.1% and is expected to reach a value of $126.8 billion by 2031. Let us move ahead and delve into the characteristics and applications of supervised vs unsupervised learning.
Types of Supervised Learning
A supervised learning model learns mapping function from input features to output categorical (classification) or continuous (regression) labels as per its training with labeled datasets that contained input-output pairs and an explicit feedback mechanism for adjusting parameters to reduce the difference between predicted and actual results. The model’s performance evaluation metrics consist of F1-score (classification), mean squared/absolute error (regression), recall, precision and accuracy rate. Majorly, types of supervised learning can be categorized based on the problem statement received:
Classification
The algorithms designed for resolving such problems assign specific categories to the input data. Some of the models are listed below:
- Linear Classifiers: These simple, computationally efficient algorithms consider all features of the input data samples and create a decision boundary using a line or hyperplane (for higher dimension) between different classes. These operate in both linear and non-linear spaces for classification, supported by optimization function, to predict desired outputs and loss function to measure the difference in desired and predicted output.
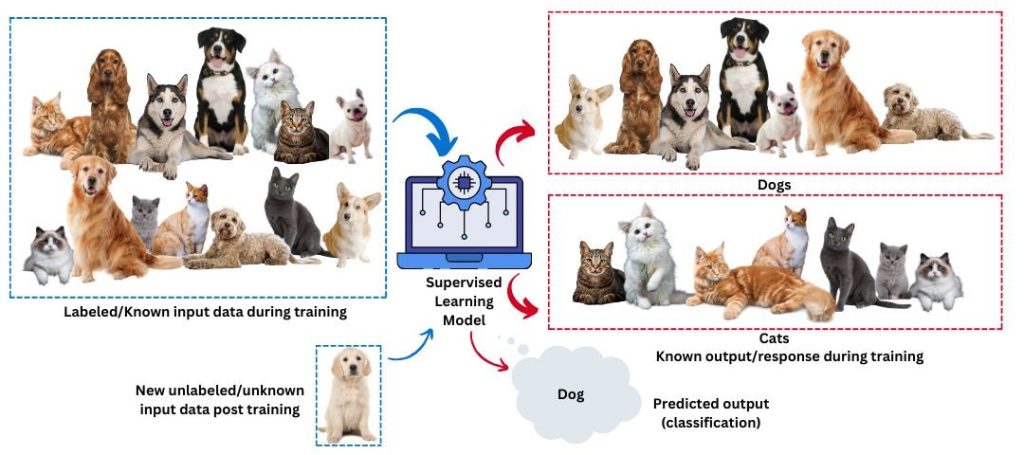
This is an example of supervised learning model that works with labeled input & output data during training
- Support Vector Machine: It is a versatile classification model that has a linear kernel and approximates a decision boundary or hyperplane to separate data points into different classes. Here, support vectors refer to the data points that lie closest to the decision surface or hyperplane and influence its position and orientation.
- Single-layer Perceptron: It represents the fundamental building block of neural network model without any hidden layer. It is used for binary classification of input data into two linearly separable classes. It takes input, computes their sum which is passed through a non-linear threshold/activation function (Tanh, sigmoid, ReLU) to determine the binary output of the perceptron, such as for simple logic operations (AND, OR and NOR gates)
- Neural Networks (NNs): These are deep learning models inspired by the human brain and are made up of interconnected layers of artificial neurons that learn complex mappings between input and output pairs. There are several types of neural networks, all of which are governed by supervised machine learning models.
- Stochastic Gradient Descent Classifier: It is a scalable, feature-scaling sensitive optimization algorithm that fits linear classifiers under loss function, by minimizing cost function and determining optimal coefficients or parameters. SGD easily handles sparse, large-scale machine learning problems and requires tuning hyperparameters like regularization parameter that controls the training data fit, outfit prevention and number of iterations impacting the algorithm’s convergence.
- Decision Trees: A tree-based type of supervised learning that partitions the feature space created from input data and predicts majority class and average target value present in each separated region.
- Random Forest: An ensemble method made up of deep decision tree combinations to improve accuracy and reduce overfitting through their average. It is trained on different parts of the same dataset to reduce variance, but this may lead to bias.
- Naive Bayes Networks: It is a linear probabilistic classification approach that is dependent on Bayes’ Theorem and assumes that the features are conditionally independent (naivety). Naive Bayes’ classification (NBC) has a single root, nodes as children of the root and with no edges present between other nodes.
- k-Nearest Neighbors: This type of supervised learning is commonly known as k-NN, is a non-parametric algorithm that functions as per the majority class of the k-nearest neighbor in the provided input feature space.
Regression
It is another type of supervised learning problem which utilizes algorithms to understand the relation between independent and dependent variables, for example, prediction of continuous numerical values using input data points. Some of the models are listed below:
- Linear Regression: It is a regression model that finds the most fitting line or hyperplane that passes through the data points and predicts a continuous numerical output. It is the simplest form of regression that is useful for statistical models.
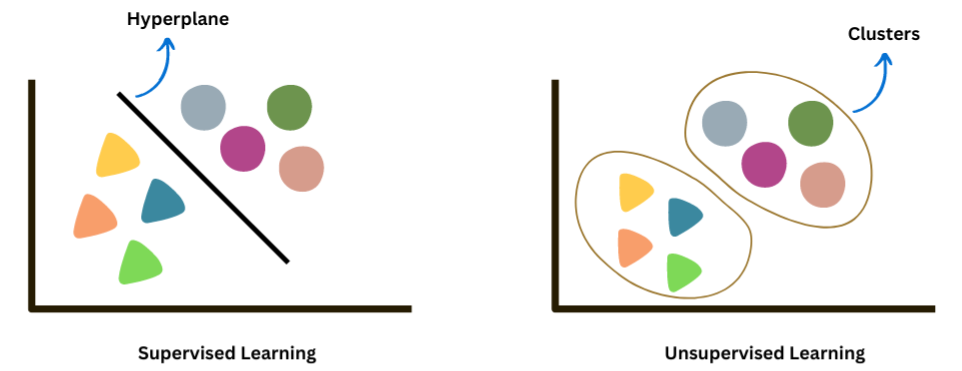
This image shows supervised vs unsupervised learning responses for unknown data post training
- Non-linear Regression: This is considered when the relation between the independent and dependent variable follows a non-linear pattern. It is a flexible model useful for modelling functional forms that do not follow linear relationships.
- Logistic Regression: It is linear binary classification model that predicts the probability of an instance belonging to a particular class by analyzing the relationship between independent and dependent binary variables. LR uses logistic (sigmoid) function that assures and maps all real values between 0 to 1 and produces a probability value (Class 0 if <0.5, Class 1 if >0.5) based on the input independent variables and predicts continuous output values. It can be used for both continuous and discrete datasets.
- Polynomial Regression: It is utilized when the relationship between independent and dependent variables is depicted using polynomial functions. It is useful in AI pattern recognition in the input data by adding high-order terms like quadratic cubic in the regression equation.
- Multiple Regression: This type of supervised learning is used to predict continuous dependent variables by using multiple independent variables. It is especially suitable for cases where several predictors influence the end outcome.
Examples of Supervised Learning
There can be a variety of use cases associated with supervised learning, such as image classification (NN), where the model recognizes patterns and conducts human detection using OpenCV within the images, to identify animals, vehicles, employee faces etc. It forms the basis of natural language processing (SGD) that is applied in tasks like customer sentiment analysis (NBC), machine translation or speech recognition (NN), text classification (SGD) and named entity recognition in intelligent document processing.
It is used in the finance sector (LR) for transactional fraud detection, stock and house prices (as per bedrooms, area) prediction, sales revenue projection, client churn prediction, credit scoring, spam mails (NBC) etc. It can also be used for developing recommendation systems for music, movies, products etc. in e-commerce, entertainment streaming and digital music platforms based on the user’s previous interactions and preferences. In the healthcare sector, it is used to predict diseases and patient outcomes, medical imaging, and identification of cancer from medical scans and historical data (LR). There can be further sub-applications of these broad areas that can be considered as examples of supervised learning.
Some common challenges faced while using supervised learning techniques include reduced data quality due to errors, biased and noisy data labeling or annotation. They require large training datasets imposing high costs and time to acquire for specialized domains. Another issue is related to overfitting where models memorize training data rather than learning generalizable patterns causing poor performance on unseen data. All this leads to inaccurate, discriminatory or unfair predictions, a crucial factor in cases of hiring and criminal justice.
Types of Unsupervised Learning
As discussed earlier, an unsupervised learning model is trained on an unlabeled dataset and does not receive any explicit guidance or guidance related to its prediction other than during its training. It strives to identify hidden structures, patterns and relations within the input data without the aid or provision of pre-defined output labels. The following are the types of unsupervised learning:
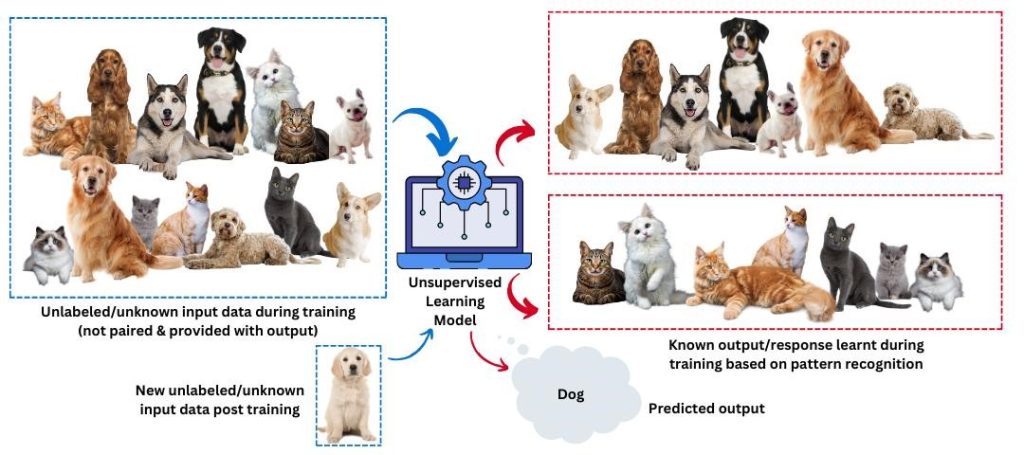
This is an example of unsupervised learning model that works with unlabeled input data during training
Clustering
Clustering is an unsupervised learning cum data mining method used for grouping unlabeled data with respect to their similarities and differences. This involves algorithms such as DBSCAN, hierarchical clustering and K-means clustering that can group similar data points into clusters with respect to their proximity in the input data feature space. In the case of K-means, the K value represents the grouping size and granularity, as this clustering algorithm assigns similar data points into groups.
Association
Association rule learning (ARL) models like Apriori, F-P growth (tree structure), Eclat etc. create and use various rules for finding relations, correlations and dependencies between variables and mine frequent patterns in a dataset. The rules are mainly if-else statements exploring variable relations. The ‘if’ element is referred to as the condition or antecedent, and the ‘then’ element as the outcome or consequent, associated with single cardinality relationships, and the cardinality increases with the increase in number of variables. Performance metrics considered for these types of unsupervised learning models are support (frequency of variable, confidence and lift (Lift = 1: ‘If’ and ‘Then’ are independent; >1: Variables are dependent; <1: One variable negatively affects another).
Dimensionality Reduction
It is an unsupervised learning technique that is utilized when there is presence of many features or dimensions in a dataset. DR reduces the number of data inputs to convert it into a manageable size without interrupting the data’s structural integrity and variance. It forms the basis of autoencoders, Principal Component Analysis and Distributed Stochastic Neighbor Embedding (t-SNE).
Density Estimation
It is another type of unsupervised learning that estimates the probability distribution of data and is used in methods like Gaussian Mixture Models, Top-hat KDE, Probabilistic Models, and Kernel Density Estimation (KDE). It can be represented using histograms that divide the data into bins, tally the data points within and shift according to data interpretations. In contrast to this, in KDE, each data point contributes to a smooth estimate curve while estimating the probability density function resulting in a non-parametric model of the data distribution which is mostly effective in low-dimensional feature space. In the case of probabilistic models, clustering data points is based on the likelihood of distribution that uncover data pattern in the distribution.
Examples of Unsupervised Learning
This type of machine learning approach is seen to be utilized in various real-life scenarios like customer segmentation in retail sector, where it generates demographic insights for similar customer purchase or bundled purchase behavior (ARL) that can be useful for market basket analysis, devising effective marketing strategies and market segmentation (K-means). It is a useful tool for organizing large collections of text, documents and images based on their features and content into clusters, for example, data generation (DE), image compression (K-means), data pre-processing, noise removal from visual data by autoencoders (DR) etc. It can make personalized recommendations (ARL) without any human intervention or feedback by discovering latent patterns in product searches and user-item interactions. A very important aspect of unsupervised learning models is their ability to detect anomalies (ARL, DE) within activities, data patterns, traffic (Google Analytics) such as during fraudulent transactions, sudden equipment failures, network intrusions etc. There can be further sub-applications of these broad areas that can be considered as examples of unsupervised learning.
Unsupervised learning presents certain challenges such as performance evaluation due to lack of ground truth labels for comparison and low scalability because of the involvement of large datasets and high-dimensional feature spaces. If the input data is not well distributed and structured, it is not necessary that it is well suited for all unsupervised algorithms and tasks and would always generate effective results with good quality. These models may also produce abstract and complex data representations, making it challenging to interpret clusters and patterns instead of simplifying the input data structure.
| Supervised Learning | Unsupervised Learning |
|---|---|
| These algorithms are trained using labeled data | These algorithms are trained using unlabeled data |
| Takes feedback to check validity of output prediction | Does not take any feedback |
| Predicts the output based on training | Finds the hidden patterns in input data |
| Input data paired with output is provided during training | Only input data is provided to the model |
| Categorized as Classification & Regression problems | Categorized as Clustering & Associations problems |
| Produces an accurate result | Produces comparatively lesser accurate results |
| Includes algorithms like SVM, Decision trees etc. | Includes algorithms like KNN, Apriori, Eclat etc. |
Best of both Worlds with KritiKal
To conclude the topic of supervised vs unsupervised learning, one can say that these are fundamental approaches in machine learning that are applied on the basis of real-life problems. The goal of supervised learning is outcome prediction for input data, where the type of results is expected to be like the ones during the model’s training. Though, the goal of unsupervised learning is to retrieve insights from large volumes of input data, that may or may not differ from expected results as per the machine learning model’s understanding. Supervised learning models can be utilized for weather forecasting, stock price prediction, customer sentiment analysis, spam detection etc., as compared to unsupervised learning models that are useful for data distribution, exploratory analysis, dimensionality reduction, clustering, anomaly detection use cases. Though both models can be written using programming languages like R, Python etc unsupervised learning is computationally more complex as it requires large, unclassified datasets and powerful tools like TensorFlow for training. Moving forward to the drawback of each of these models, one can say that supervised learning requires a lot of time for training and expertise in data annotation that may be biased, while unsupervised learning can generate inaccurate results without human intervention.
A high-level amalgam of both models is semi-supervised learning trained on unlabeled and labeled datasets. It is usually considered when feature extraction from data is difficult and high volume of input data is involved. It is especially beneficial for medical imaging as it generates accurate results, for example, instead of the whole dataset, a small subset of medical scans is labeled for tumors, so that accurate predictions related to progress of the patient’s health can be made, or when they may require more medical attention.
KritiKal Solutions has developed many computer vision solutions for SMBs in the USA and Fortune500 companies. We have worked on various projects involving supervised and unsupervised learning such as classification of horizon and non-horizon areas, valid and non-valid traffic lights to reject false positives, shelf and bottle detection, medical imaging and embryo grading solutions, skin and hair analysis, image denoising autoencoder architecture on MNIST data, determining wine quality based on parameters, among others. Please call us or mail us at sales@kritikalsolutions.com to resolve challenges related to these camera systems. Both supervised and unsupervised learning techniques perform crucial roles in multiple machine learning applications by offering complementary perspective to the obtained input data. The need of the hour is for businesses to develop industry-agnostic versatile models by leveraging the strengths of both of these types of machine learning approaches.

Renuka Patnaik currently holds the position of Lead Engineer (Computer Vision Systems Design and Development) at KritiKal Solutions. In addition to being an IITian, she has more than 10 years of experience in this field. She is highly skilled in machine learning, deep learning, pattern recognition, CNN, ANN, image processing, and other programs and platforms such as MatLab, Python,LaTeX etc. She has efficiently helped KritiKal in delivering various successful projects to some major clients.