

 Global
Global  United States
United States 
What is Multimodality?
Multimodality refers to the capability of generative AI to produce outputs in various types of modalities, such as images, audio, text, sensory data, etc. as per the inputs that have been provided from multiple modalities or data sources. Multimodal large language model (LLM) can process, learn statistical patterns, integrate, and generate new data similar to their training dataset in terms of style and content. For example, if a multimodal AI system is trained to generate textual descriptions for sample images or generate speech from prompt texts, it can easily generate diverse and nuanced results when provided with respective inputs in real time. That is, multimodal AI offers versatility and flexibility in data type handling and applications, while multimodal LLMs are largely centered around language-related applications. As a part of generative AI services, it is a continuously emerging field and is enhancing the methods of interaction between humans and technology. It finds an important role in the development of AI models across industries for the creation of art, virtual assistants, chatbots, and more.
Natural Language Processing (NLP) falls under the umbrella term AI as an innovative subfield focusing on interactions and translations between humans and machines, by enabling the latter to process, understand, and generate conversations with the help of computational linguistics and machine learning. The system divides textual input like words or sentences into smaller units (tokenization), reduces words into base (stemming) or root forms (lemmatization), identifies, and classifies textual entities like organizations, names, places, and dates (named entity recognition), determines sentiments, and emotional tones in the given text (sentiment analysis), and even translates text from one language to another (machine translation). It finds applications in various industries, including customer assistance using chatbots, spam detection, textual summarization, social media promotions, etc.
The global market size of multimodal large language model was estimated to be US $844 million as of 2024 and is expected to grow at a CAGR of 53.9%, reaching an estimated value of US $11240 million by 2030. The natural language processing market was valued at US $37.1 billion as of 2023 and is expected to reach US $453.3 billion by 2032, increasing at a CAGR of 33.1% during this forecast period. Both these fields are experiencing rapid technological advancements, increasing data and management techniques, and leading to the development of various commercial applications such as voice sense, change effect analysis, surging complexity in businesses for industrial growth, etc. Let us explore more about multimodality, the history of multimodal LLMs, and its applications in natural language processing in this article.
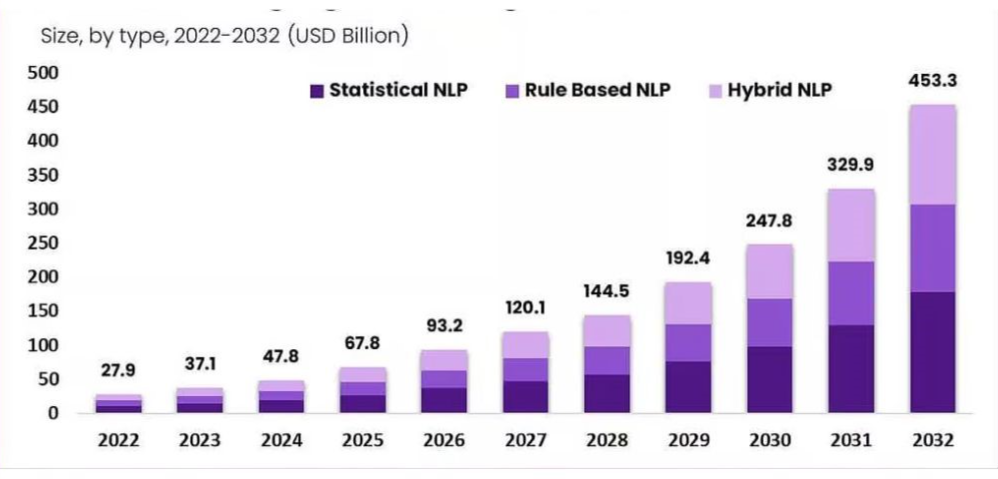
Global market size of natural language processing backed by multimodal language model
A Brief Timeline of Multimodal LLM
Given below is a brief account of major breakthroughs and the advancements in the field of multimodal LLMs over the past few years:
2014: The combination of textual and image data for captions laid the foundation for multimodal learning and the generation of textual descriptions for images, for example, Google’s Show and Tell captioning system.
2015: Visual Question Answering (VQA) is introduced at Stanford, a model that answers questions related to images, paving the path for visual and textual data integration.
2017: Multimodal Tucker Decomposition Attention Networks (MUTAN) were developed that were capable of combining visual and text input data with the help of attention mechanisms for captions and VQA. In addition to this, the Generative Pre-trained Transformer (GPT) text-based language model was released by OpenAI.
2018: More systematic efforts were put in for developing multimodal language model and embeddings representing text and images, especially after the introduction of the Contrastive Language Image Pre-Training (CLIP) deep learning model by OpenAI. This year also saw the rise of Bidirectional Encoder Representations from Transformers (BERT) by Google AI. It utilized transformer architecture capable of processing input data in a parallel manner instead of sequentially allowing complex AI pattern recognition in sentences and NLP.
2019: VisualBERT, a model that combines text and images and processes multiple modalities with a transformer came onto the market. The second iteration, GPT-2 with a more powerful architecture and a larger model size than the BERT was released. This allowed it to conduct various NLP tasks such as textual summarization, completion, human-like text generation, and machine translation.
2020: This year marked the release of Bidirectional and Auto-Regressive Transformers (BART) by Facebook that combined various aspects of bidirectional and auto-regressive learning from BERT and GPT-2. This multimodal LLM is majorly trained on text and codes, is especially used in the research industry, and can easily generate coding for performing tasks such as translation, summarization, and answering.
2021: The third iteration, GPT-3 with billions of parameters, was released by OpenAI. It has the capability of composing poetry, programming assistance, human-like text and content generation, and web page designing. Furthermore, ChatGPT was released this year, which was initially powered by GPT-3.5 for transforming human-machine interactions. DeepMind released the Flamingo model that blends human language and vision via multimodal language model learning for VQA. OpenAI also introduced DALL-E, that generates images from text prompts.
2022: DeepMind released Gato, a single multimodal architecture-based generalist model that creates texts, processes images, and can be used in robotics. Pathways Language Model (PaLM), a text-focused model, was introduced by Google that showcased generalization capabilities at large scale.
2023: Larger and more powerful models than GPT-3 that can create more natural and user-friendly applications, such as GPT-4 with multimodal capabilities of taking in text and images as inputs, were released. Google Gemini 1.5 enhanced multimodal learning and subsequent integration of linguistic and visual data for performing various tasks.
2024: OpenAI has added vision capabilities to ChatGPT that allow it to perform image-based queries with the help of multimodal LLMs.
Applications of Multimodal LLM in NLP
We learned in the above section about the various advancements in this field in recent years. Pre-trained multimodal large language model is enabling enhanced performance levels, futuristic possibilities and impacting natural language processing positively. Moving forward, let us explore how these contributions are accounting for the progression of NLP:
Diverse Data Handling
Traditional large language models such as GPT-3 and BERT were trained to process textual information only, but with time, this capability has been enhanced to comprehend multiple data types, including audio, video, sensor data, and images at the same time. These models can handle multiple modalities simultaneously instead of one modality in isolation, can process diverse types of information at once, and relate to generate different data forms as well. For example, a multimodal LLM can analyze an image and generate descriptive text and vice versa for easier interpretation using both visual and verbal inputs. As a part of AI development services, these also assist in cross-modality learning from textual and visual data for improving automated annotation, image captioning, data labeling, and the accuracy of AI models
Contextual Understanding
Since multimodal models can easily handle multiple data inputs, they assist users to gain a better understanding of the context, especially in the case of real-world situations where data may be present in different modalities. A multimodal language model can improve contextual understanding by comprehending the same emerging from textual interactions, media, etc., similar to humans who communicate through verbal linguistics, body language, facial expressions, visual cues, etc. For example, the model is given an input image of a dog that reads the caption “The dog is playing with a ball” and is able to understand both textual and visual inputs for a more robust perception.
Improved Accessibility
These models find their applications across various domains by enabling enhanced interactions in terms of accessibility and user-friendliness. For instance, in the healthcare industry, multimodal large language model is used to analyze X-rays, MRIs, other medical images, and patient records in textual form to generate accurate diagnoses. Also, in the gaming industry, these models generate characters that are capable of responding to visual and textual stimuli in real-time as well as interactive content for amplifying user experience.
Various applications of multimodal LLM in NLP
Enhanced AI Experience
Users can easily interact with AI systems using multimodal capabilities in lieu of simple text commands or a singular input method. These models create a rich AI experience by allowing users to interact through voice, gestures, and images, opening the doors to newer possibilities for AR/VR systems, robots, and smart assistants. For example, a broken device can be repaired using instructions provided by an AI assistant that responds as per the input appliance images and manual text query.
Cross-Domain Knowledge Transfer
With multimodal LLMs, the knowledge of one domain can be transferred to another by utilizing different types of inputs. For example, a multimodal large language model trained in scientific literature will be able to understand images from the same domain and allow disciplinary knowledge to transfer a smoother process. These models can be used to search multimodal data, including images, text, images, sounds, with higher accuracy.
Industry-Agnostic Applications
A multimodal language model and generative AI in retail can empower visual search engines such applications to assist users with product search. They combine textual search and image recognition to provide better results. These models can integrate medical image analysis with text-based research documents and health records to generate accurate clinical decisions and diagnostic support. In the education industry, these models can be used to develop personalized learning tools to combine text, interactive content, and visual data for tailoring resources as per students’ individual needs. These language models also aid in the development of robots that can process visual inputs and human language to perform complex tasks in dynamic environments. These models foster creativity in the entertainment industry by generating movie scripts, storyboard, artistic images, music, textual descriptions, digital designs, as well as interactive experiences based on combined inputs of visual and textual stimuli.
Future of Multimodal LLM
Open-source language models enable developers and researchers to form new applications and tools using pre-trained model libraries, web apps for text generation, frameworks for fine-tuning, language translations, etc., for example, Hugging Face provides accessible and user-friendly open-source models. Some applications may include GPT-4 based chatbots for customer services, gaming, edtech, virtual assistants for making appointments, searching for information, smart home appliances management, as well as content generation for social media, news articles, marketing campaigns, blogs, short and long-form texts, etc. For example, a multimodal generative AI model or chatbot can answer a user’s query related to the working of a device by showcasing stepwise images and video clips, thus personalizing and enhancing their experience and engagement. Also, they can create artwork combining specific auditory and visual elements for developing immersive experiences, music that showcases dynamic, unique, and expressive composition, and other forms of output that reflect diversity and complexity similar to human creations.
Certain challenges that developers face during the creation and training of a multimodal LLM include gathering large amounts of diverse datasets and gaining expertise in specialized techniques that can handle multiple modalities. This is because the models need to understand and recognize statistical patterns connecting images and texts, or texts and speech, and generate outputs in a similar manner.
Conclusion
The field of Natural Language Processing currently faces several challenges, such as biased training data, misinterpretation, newly emerging vocabulary, differences between body language and verbal delivery, etc. Despite these issues, the rapid progression of the development of LLMs is enabling newer possibilities, especially in the field of natural language processing that can be accessed through powerful platforms. KritiKal Solutions can assist in the development of state-of-the-art NLP-based solutions powered by LLMs working on different modalities as well as in implementing generative AI in cybersecurity. We can assist businesses in evolving through no-code solutions and domain experts to achieve better large model performance with low computations and complexity at reduced costs. We have ample experience in working with SMBs and other organizations in developing solutions such as searching multimodal information in databases, generating textual descriptions from educational images in real-time, and various other use cases. Please get in touch with us at sales@kritikalsolutions.com to discuss your multimodal language model-related requirements and demonstrations related to the same.

Sarthak Zalte currently works as a Software Engineer at KritiKal Solutions and has hands–on experience in designing and implementing robust backend solutions using Java, Spring Boot, and MySQL. With a strong foundation in data structures, object-oriented programming, and a result-driven approach, he has developed and maintained RESTful APIs and business logic for applications, enhancing functionality and user experience for KritiKal’s clients.