

 Global
Global  United States
United States 
What are Data Annotation Services?
Data annotation or labeling is the process of tagging or labeling objects and patterns in a dataset, which is further used for training machine learning algorithms. Such a process has numerous applications, for example, annotating patterns in audio files, text files for developing natural language processing algorithms for, conversational AI, voice transcription recognition models etc. Data annotation services insinuate mapping of objects and patterns in images, videos, files containing customer purchase history and so on, to an AI model. The model eventually trains on the annotated dataset and understands what is expected of it to describe, classify, and recognize from real-world contextual information.
It is necessary to note that labels assigned to objects and patterns ought to be aligned with the objectives and outcomes of interest, per say, specific to medical, healthcare, environmental, defense manufacturing industries. This is where data annotation services come into the picture that generate labels and perform annotations pertaining to integral part of algorithmic model training, especially, when utmost data privacy, quality and accuracy are of crucial concern in the process to get expected results. As per a Medium report, the data annotation services market is surging at a CAGR of 25% in the forecast period 2021-2026. Data labeling and annotation services ensure that quality is maintained for data-centric model training. A MIT study suggests even though the best practices for annotation, such as use of benchmark datasets. are followed, about 3-4% of labels turn out to be inaccurate. With annotation services, customers can benefit from regular feedback, dashboards etc. that may reduce occurrences of mislabeled images, inaccurate, insufficient, biased or unbalanced data results etc.
How Do Data Annotation Services Work?
Data annotation processes are required to automate various repetitive, tedious and slow-moving tasks that can be run by machine learning models. Alongside this, they also make it possible for the processes to become accurate and scalable in nature. The steps to annotate input data for training AI/ML models boil down to the following:
Data Collection
Large-scale image or textual datasets of good quality can be collected from open domains, such as Place365, COCO, ImageNet etc. Usually, high-quality annotated data of a particular nature is difficult to obtain from public domains, and thus, annotations need to be constructed from raw data collections. This process requires multiple tests to ensure accuracy and noiselessness. Alternatively, self-annotated datasets can be formed by annotating raw data collected from open sources like CreativeCommons, Unsplash etc. Another method for data collection is web scraping using scripts that repeatedly search and save relevant images. The raw data collected requires cleaning prior to annotation, nevertheless the data is already known to belong to specific classes, thus requiring only single tags.
Data Preparation
Data annotation outsourcing services provide advanced dataset management and organizing options. Customers can upload data using respective features like drag and drop tool, on the software or webpage interface. They provide a command line interface for data upload as well. The video of interest can be imported at a frame rate of choice, for example, object detection requires a video frame rate of 1-2 frames per second, while movement tracking requires 25-30 frames per second. The commonly supported formats include .avi, .mp4 and .mov files. Notably, the number of imported frames is directly proportional to the project’s size, a frame rate that gives the highest accuracy or lower training data should be chosen in this case.
Label Creation
Data annotation outsourcing services choose the right specific classes from the available annotation classes, for example, in case of automated traffic video data annotation, new polygon class label can be created such as car, bicycle or a skeleton class with a unique ID like a pedestrian. The developed software interface usually contains options to change or add new classes with different colors, short descriptions, such that it can be easily understood. User defined labels can also be added in annotation tool
Annotation
The object in the input data is selected and a new keyframe is generated. Data annotation services offer real-time collaboration within the entire team that in turn speeds up the annotation process and keeps everyone informed. The annotation software has sub-annotations involving Instance ID, Attributes, Text, Direction Vector, Comments, Tags etc. There are specific parameters like fine/coarse etc. that can help reduce the number of polygon mask edges for easy processing. Some software are additionally gimmicked with manual area selection, inclusion and exclusion of frame parts and other features. While using the software, one needs to annotate only some keyframes in the input data, automatic interpolations are created in between them.
Either the manual process or the automated data labeling and annotation process can be rerun across the input data for creating new keyframes. This is to go through several frames, adjust general selection, transform the polygon and adjust for changes and motion in the input data. Every time the polygon is recalculated, new keyframes are generated in the timeline (for navigation between frames), which can be removed as per convenience and requirement for accuracy. Using bounding boxes of adjustable sizes and keypoint skeletons are often considered easier ways of annotating data via some manual adjustments. For example, stick like figure or a skeleton representing a pedestrian, or repositioning joints to match a hockey player’s pose by selecting specific nodes. In case of occlusion and data fragment mismatches, inclusive keypoints can be removed by clicking on the relevant areas of frame. It is ideal to add keyframes every 2-5 frames until the whole input data is annotated for accurate interpolation between keyframes.
Use Cases of Data Annotation Services
Data annotation services deploy various algorithms ranging from bounding boxes, pixel-level segmentation masks, sentiment analysis, to landmark annotations for pose estimation etc., to label or tag elements in visual data and high pattern recognition. These algorithms are also useful in automating the entire annotation process and provide plenty of use cases, some of which are mentioned below:
Textual Data
Data labeling and annotation help in identifying classes within the textual input data, for example, name, address, organization, city, location, date, license number and much more through named entity recognition. It can be used for sentiment analysis for labeling textual (product review) data as per their sentiment polarity (neutral, negative or positive) and emotions expressed. It can also be used for text classification and textual document categorization as per pre-defined criteria, labeling social media posts, profiles, comments, etc. for user profiling, platform moderation, topic modeling, sentiment analysis, brand monitoring and more. An example of open-source model for annotating textual data is TextBlob.
Audio Data
Data annotation can be used for speech recognition, transcription of spoken audio into textual format, labeling audio segments with the speaker’s emotional states and speaker diarization that is identifying the speaker in the audio recording. A few examples include LibriSpeech labeled dataset, Google Speech Commands, Mozilla Common Voice etc. An example of open-source model for annotating audio data is Audino Annotation Tool.
Time Series Data
Data labeling and annotation are used for labeling time series data to identify anomalies, outliers and abnormalities in patterns. A very useful use case of annotating historical time series data is training predictive maintenance models and forecasting. The latter can be applied for weather forecast, telecommunications network monitoring, healthcare and vital signs monitoring, financial forecasting, manufacturing supply and demand forecasting, energy consumption forecasting and so on. An example of open-source library for annotating time-series data is CrowdCurio.
Structured Data
Certain machine learning tasks such as regression and classification require labeling of rows, columns or whole tabular data. Databases with metadata, relationships etc., can be annotated for better data management and analysis. It can be useful for businesses for upselling, cross-selling, personalization, campaign optimization, customer segmentation, data linking such as common measurement units, sentiment analysis, customer lifetime value analysis, geospatial analysis, quality control and data normalization. An example of open-source model for annotating structured data is TableLlama.
Sensor Data
Annotation of sensor data obtained from IoT devices can be used for various applications like environmental monitoring and predictive maintenance of industrial machines. For example, faulty machines may be featured with labels such as bearing wear, excessive vibration, overheating, abnormal pressure drop etc. An example of open-source model for annotating sensor data is LATTE.
Financial Data
Financial data and transaction annotation is used for training fraud detection and risk management models. Historical stock market data is labeled for trend predictions, analysis and building high-frequency live trading algorithms. Some financial data annotations may include Relative Stock Index and Moving Average Convergence Divergence, open, high, low, close pricing values by using open-source tools like CVAT etc.
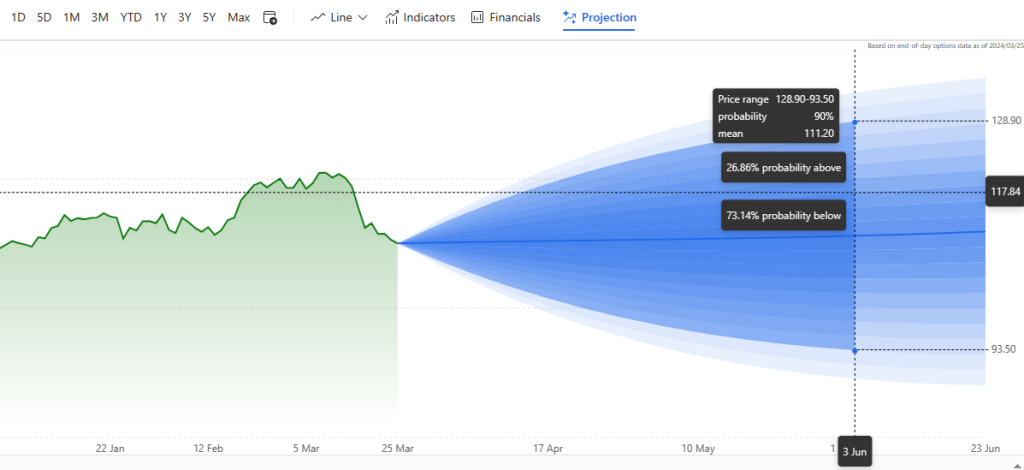
The above diagram shows application of data annotation services to predict Abbott’s stock prices
Advanced Solutions Using Data Annotation Services
Ongoing advancements in data annotation are marked by automation, accuracy and efficiency. With models being developed with active learning and quality assurance capabilities, annotation workload and costs are likely to be reduced. Apart from the above use cases, integrations of AI/ML frameworks are making image annotation services pipelines more seamless, while development of emerging technologies like autonomous robotics and augmented reality, is on the edge. Given below are the latest evolving algorithms of data annotation and respective examples:
Object Detection
The training dataset composed of images (.png, .jpg) and videos (.mov, .avi) is labeled using bounding box annotation and polygon-based annotation.
- You Only Look Once: It is an algorithm which is also known as YOLO, usually used in fast and accurate object detection. It divides the input data into numerous grids and forecasts bounding boxes as well as category, class or label probabilities for each of those grids. It is seen to be applicable in vehicle detection, traffic analysis, autonomous driving and connected vehicles.
- Faster R-CNN: The algorithm is called Region-based Convolutional Neural Network. It is composed of two steps, where the first one proposes ROI or regions of interest with the help of Region Proposal Network (RPN), and the second one classifies and refines these ROIs. It is seen as applicable in retail technology solutions such as inventory management, security and surveillance, autonomous vehicles, defect detection, wildlife monitoring etc.
- Single Shot Multibox Detector: The SSD algorithm detects objects and patterns obtained by using feature maps at multiple scales and predicts bounding boxes and probabilities of class to be assigned to them. Given that it doesn’t require the additional RPN step, it is faster than the R-CNN algorithm. Some applicable use cases of models trained on datasets with this type of data labeling and annotation include crowd monitoring, inventory management, identifying objects or people of interest in security footage, and more.
Sematic Segmentation
The training dataset composed of images (.png, .jpg) and videos (.mov, .avi) is labeled using pixel-wise annotation as well as polygon annotation.
- U-Net: It is a convolutional neural network mainly designed for biomedical image segmentation but can be architected for various use cases as well. It preserves spatial information of the object of interest and utilizes an encoder-decoder structure with skip connections to function. It is seen to be applicable in various industries, such as for tumor detection in MRI scans, cell segmentation, organ segmentation in CT scans, object-based image analysis from satellite imagery, land cover classification, manufacturing defect detection, and so forth.
- FCN: The Fully Convolutional Network algorithm enables end-to-end pixel-wise prediction by replacing fully connected layers with convolutional layers in semantic segmentation. Its applications include scene understanding in ADAS, anomaly detection in quality control and disease detection.
- DeepLab: It is a deep convolutional network that uses atrous or dilated convolution forms the basis of a series of semantic segmentation models by capturing multi-scale contextual information. Some of the use cases of models trained on datasets with this type of data labeling and annotation are tumor segmentation, urban planning and environmental monitoring for vegetation analysis.
Instance Segmentation
The training dataset composed of images (.png, .jpg, .bmp) and videos (.mov, .avi) is labeled using pixel-wise annotation.
7. Mask R-CNN: It is a modified version of Faster R-CNN with an added branch of segmentation masks prediction. Like Faster R-CNN, it uses bounding boxes and class labels for object detection and instance segmentation. Mask R-CNN is useful for pedestrian detection by autonomous vehicles, interactive image-editing tools, tumor localization, movement tracking of people of interest, suspicious object detection in public places etc.
8. Panoptic FPN: Panoptic Feature Pyramid Network is a unified model that handles objects of different scales and performs panoptic segmentation by combining instance and semantic segmentation in a single framework. It is used in disaster response, damage assessment, resource allocation, wildlife monitoring, population tracking, holistic environmental analysis etc.
Keypoint Detection
The training dataset composed of images (.png, .jpg), videos (.mov, .avi) and sensor data (.bag, .pcd, .ply) is annotated using keypoints or landmark points on the object as the basis of classes.
9. OpenPose: It is a landmark detection algorithm that estimates body joint locations such as elbows, knees, and facial landmarks such as nose, eyes in real-time from the input data. Pose keypoints need to be marked during annotation in this case. OpenPose is a very useful algorithm that finds its way in sports analytics, movement tracking, posture analysis, rehabilitation monitoring, pose recognition, customer behavior analysis and more.
10. HR Net: The High- Resolution Network is a landmark detection algorithm that captures fine-grained details during keypoint localization by maintaining high-resolution representations. This advanced solution is utilized in fine-grained manipulation tasks by robots, motion capture systems, AR-based realistic pose estimation and enhanced immersive experience.
Optical Character Recognition
The training dataset composed of images (.png, .jpg), videos (.mov, .avi) and texts (.pdf, .txt, .doc, .xlsx, .csv) is annotated using bounding boxes to localize and classify objects.
11. Tesseract: It is an open-source OCR engine that recognizes text in the input data and scanned documents. It is trained on various custom datasets to make it compatible with various languages and font types, without altering performance results. Tesseract finds practical applications in document digitization, text extraction, license plate recognition, translation of text from images in mobile applications, data entry automation, and other administrative tasks.
12. CRNN: It is a deep learning algorithm called Convolutional Recurrent Neural Network that recognizes end-to-end texts to provide robust OCR solutions. It combines recurrent layers that perform sequence modeling and convolutional layers that extract features. CRNN is used for conversion of text into machine readable format, digitization of handwritten documents, extraction of textual information from radiology images, disease diagnosis etc.
Sentiment Analysis
The training dataset of opinion mining mainly of formats like .json,.xml, .csv, involves annotating text data with sentiment labels.
13. BERT: The Bidirectional Encoder Representations from Transformers is a model trained on large text corpora and understanding text semantics and context. It is fine-tuned to perform other tasks such as sentiment analysis. BERT is used to enhance chatbot conversational abilities, understand query contexts, social media monitoring, capture nuanced learning and machine translation, and other natural language processing tasks.
14. VADER: It is a rule-based sentiment analysis tool called Valence Aware Dictionary and sEntiment Reasoner. It assigns or labels specific scores to social media texts based on a pre-set lexicon of rules and words. VADER is seen to be used for assessing sentiment in social media posts and tweets, customer feedback analysis, brand reputation management, political analysis by tracking public sentiment towards candidates etc.
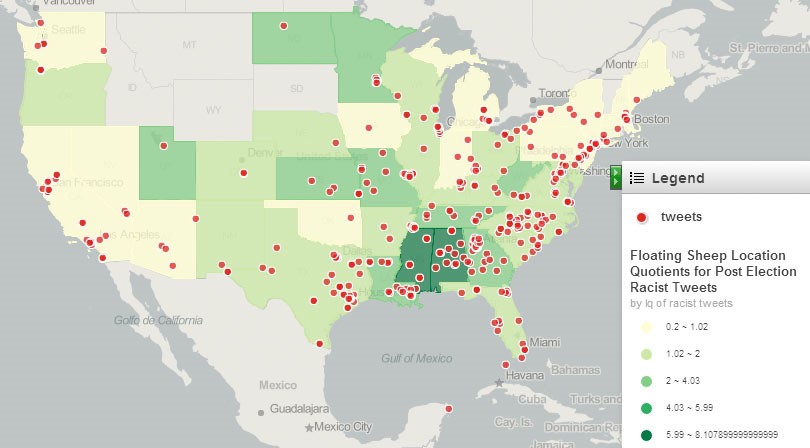
The above diagram shows data annotation services used for social media monitoring
Emotion Recognition
The training dataset is composed of images (.png, .jpg, .bmp), videos (.mov, .avi, .mjpeg), for natural language processing and other related tasks involve annotating text data with emotion labels.
15. FER: The Facial Expression Recognition deep-learning algorithm recognizes emotions from facial expressions by training convolutional neural networks on labeled datasets that consist of images with keypoints drawn on the face. FER is employed for assessing emotional responses, user experience research, facial cues and suspicious behavior detection, patient monitoring, adaptive learning, workplace safety etc.
16. AffectNet: It is basically a large-scale dataset that contains annotated facial expressions, discrete emotion labels and is used to train models for classification of emotion from facial data and emotion recognition. AffectNet can be seen employed for mental health research by detecting emotional states, developing targeted ads based on viewer reactions, creation of empathetic human-machine interfaces, emotion-driven interactions in gaming etc.
Line & Curve Detection
The training dataset composed of images (.png, .jpg, .bmp), videos (.mov, .av, .mjpegi) and sensor data (.bag, .pcd, .ply) is annotated using line segments and coordinates.
17. Hough Transform: This algorithm detects lines and curves by representing lines in image data space as points in parametric space. It pinpoints and identifies peaks in the accumulator space. This advanced solution is used to detect circular structures like tumors, quality control in manufacturing, identifying and analyzing astronomical patterns, object and lane detection etc.
18. Canny Edge: Canny Edge Detector combines edge thinning, non-maximum suppression, and hysteresis thresholding to generate clean edge maps. It identifies edges by detecting local maxima in gradient magnitude. It can enable precise navigation, identify anatomical structures in medical imaging, conduct defect detection in industrial inspection etc.
Depth Estimation
The training dataset is annotated by assigning depth values to pixels in the image through disparity maps. The most common input file formats are images (.png, .jpg, .bmp), depth maps (.exr), videos (.mov, .av, .mjpegi) and sensor data (.bag, .pcd, .ply, .xyz, .las) etc.
19. Monocular Depth Estimation: This algorithm predicts depth maps of input data using deep neural networks by leveraging techniques as a type of supervised learning and multi-scale feature fusion. It is deployed for scene understanding and object manipulation in robotics, depth-aware visual effects in cinematography and video games etc.
20. Stereo Matching: The algorithm matches corresponding data points between two or more images while estimating depth from stereo image pairs. The disparity in pixel intensity is helpful for computing depth maps as per triangulation principles. This advanced solution is used for depth perception in AR, realistic virtual object placement in real estate, hospitality and tourism industries, 3D reconstruction in healthcare, scene analysis etc.
About Data Annotation Outsourcing Services
Data annotation outsourcing services follow some ideal practices in key annotation steps of data for training machine learning models include maintaining quality of content, using lossless frame compression, avoiding low light conditions while recording and image noises, keeping datasets, files, libraries, classes and workflow organized under consistent, uniform and standardized naming conventions susceptive to varying degrees of data sensitivity, adding tags, unique IDs, colors and descriptions, using Z-stacking or Z-axis order to deal with different layers of overlapping objects in tricky backgrounds, creating accurate interpolation and keyframe annotations by going through entire footage before the procedure, importing split shorter video files of 1000-3000 frames or small pilot datasets before scaling to increase performance, supporting varied types of native file and data formats such as DICOM, NIfTI,, SAR etc.
Data annotation outsourcing services develop clear annotation guidelines and standard operating procedures that suit the client organization’s requirements. They design a customizable alternative workflow to minimize the time required to fix errors and bugs during data processing, all while assuring quality control and apt feedback retrieval. Another important step that is followed by data annotation services is ensuring data privacy and security, for example, removing personally identifiable data markers and metadata, maintaining audit trails and compliance with regulatory bodies. Although data annotation services are much more profitable, customers can choose between buy versus build options based on use cases, tools, reviews, case studies, pricing, features, source, platform, dataset, duration, resources etc.
Conclusion
Data annotation can be a very cumbersome sub-process of data management. It forms the baseline for high-precision algorithmic training. It is necessary to conduct proper annotation to save time along the pipeline during model development. In this blog, we delved into the method of data annotation, various advanced solutions developed from such annotated datasets, their use cases and best practices followed by data annotation outsourcing services. KritiKal Solutions is a leading data annotation company that has provided annotation services in more than 120 locations, tagged over 2.5K GB and 150+ million images, processed over 100K videos and completed 1K+ projects related to data annotation across industries. Leverage our expertise to gain a competitive edge in the market with high-performance model training. Please mail us at sales@kritikalsolutions.com to avail our services.

Hitesh Suyal holds the position of Associate Architect at KritiKal Solutions. He has over 7 years of experience with a demonstrated history of working in the Information Technology and services industry. With his strong engineering background skilled in Python, Computer Vision, Deep Learning, OpenCV, Spyder, Microsoft Visual Studio C++, Amazon Web Services (AWS) and more, he has helped KritiKal in delivering successful projects for some major clients.